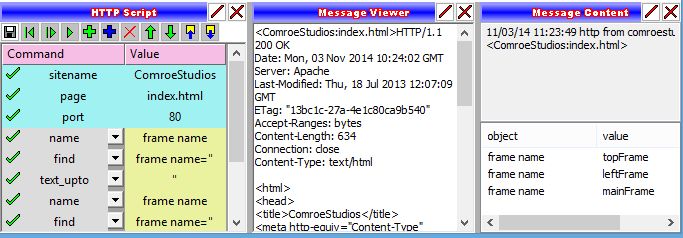
Webpage scraping scripts can be authored and tested interactively. Script commands can be authored in an interactive environment where changes can be executed immediately or single-stepped instruction by instruction to simplify the task of extracting anything contained in a fetched webpage.
Interactive webpage scraping utilizes 3 ScanEngine Explorer panels:
This panel must contain the contents of the fetched page. This is accomplished by either freshly fetching the sitename:pagename using the Web Fetch panel, or selecting a previously fetched sitename:pagename from the Message Log panel.
Please note that webpages are not inherently graphic in nature ... webpages are textual as fetched by the HyperText Transfer Protocol (HTTP). They appear graphical when viewed by a web browser only when image references to graphic files are fetched by subsequent fetch transactions (perhaps many to fill out complex webpages). To scrap text from a webpage one must first recognize which page contains the text, fetch that page, and then isolate the content for scraping by interactively authoring a webpage scraping script.
A webpage scraping script can be interactively authored and tested from this panel. As execution is single stepped, currently selected content will be highlighted in the message viewer panel, and webpage contents will be extracted (and named) in the message content panel.
Scraped content from the currently displayed message in the message viewer panel is named and placed here according to the instructions executed from the HTTP Script panel. Content scraped here from the webpage can be logged, charted, saved to database, or generally read or manipulated by script in any way imaginable.