ScanEngine Explorer can interrogate webpages. More than that, it can extract select information from a retrieved webpage, known generally as webpage scraping. Then, information scraped from a webpage can be monitored, charted, logged, saved, or acted upon by script just like any other piece of data.
An HTML Script is the means through which you designate what information should be scraped from a webpage and what name it will be known by. Any page can scraped, and the HTML script defining what information should be extracted is specific to that page. So ScanEngine Explorer permits the user to create any number of HTML scraping scripts for different pages.
Many different web sites may have identically named webpages ... such as index, status, info, about, contact, etc. On the other hand, many managable devices have built-in webpages where the page structure is absolutely identical in each identical device ... such as radios, routers, switches, etc. To keep this all straight, ScanEngine Explorer uses a naming convention for HTML scripts consisting of sitename:pagename. Sitename is for you to assign to stand for a given website or model device, while pagename is the URL suffix that follows the site / device's domain name or IP.
Finally, all the HTML scripts for a specific sitename will be kept in a common file in the HTML folder with a ".sch" file extention. ScanEngine Explorer doesn't need to load every HTML scraping script every time it runs. The user can select an appropriate subset of sitename HTML scraping scripts at program load time, or when running in a personalized environment.
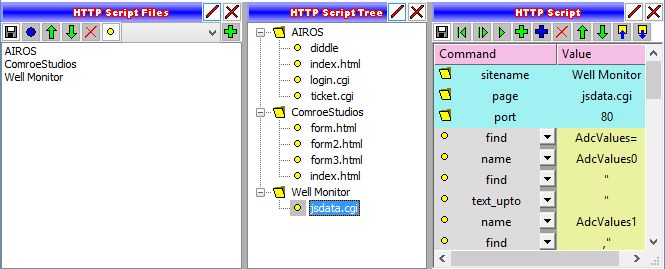
The HTML Files panel displays the currently loaded subset of HTML scraping scripts (by sitename). The HTML Tree panel displays the sitename:pagename for all the currently loaded HTML scraping scripts. Finally, the HTML Script panel displays the currently selected HTML scraping script.